Pose-Oriented Scene-Adaptive Matching for Abnormal Event Detection
A Novel Framework for Intelligent Surveillance Systems
Abstract
For intelligent surveillance systems, abnormal event detection automatically analyses surveillance video sequences and detects abnormal objects or unusual human actions at the frame level. Due to the lack of labelled data, most approaches are semi-supervised based on reconstruction or prediction methods. However, these methods may not generalize well to unseen scene contexts.
To address this issue, we present a novel self and mutual scene-adaptive matching method for abnormal event detection. In the framework, we propose synergistic pose estimation and object detection, which effectively integrates human pose and object detection information to improve pose estimation accuracy. Then, the poses are resized to reduce the spatial distance between the source and target domains.
The improved pose sequences are further fed into a spatio-temporal graph convolutional network to extract the geometric features. Finally, the features are embedded in a clustering layer to classify action types and compute normality scores.
The training data is taken from the training part of common video anomaly detection datasets: UCSD PED1 & PED2, CHUK Avenue, and ShanghaiTech Campus. The proposed framework is evaluated on video sequences with unseen scene contexts in the UCSD PED2 and ShanghaiTech Campus datasets.
The detection accuracy and efficiency are also evaluated in detail, and the proposed method for abnormal event detection achieves the highest AUC performance, 84.6%, on the ShanghaiTech Campus dataset and relatively high AUC performance, 96.9% and 74.8%, on UCSD PED2 & PED1 datasets. Compared with other state-of-the-art works, the performance analysis and results confirm the robustness and effectiveness of our proposed framework for cross-scene abnormal event detection.
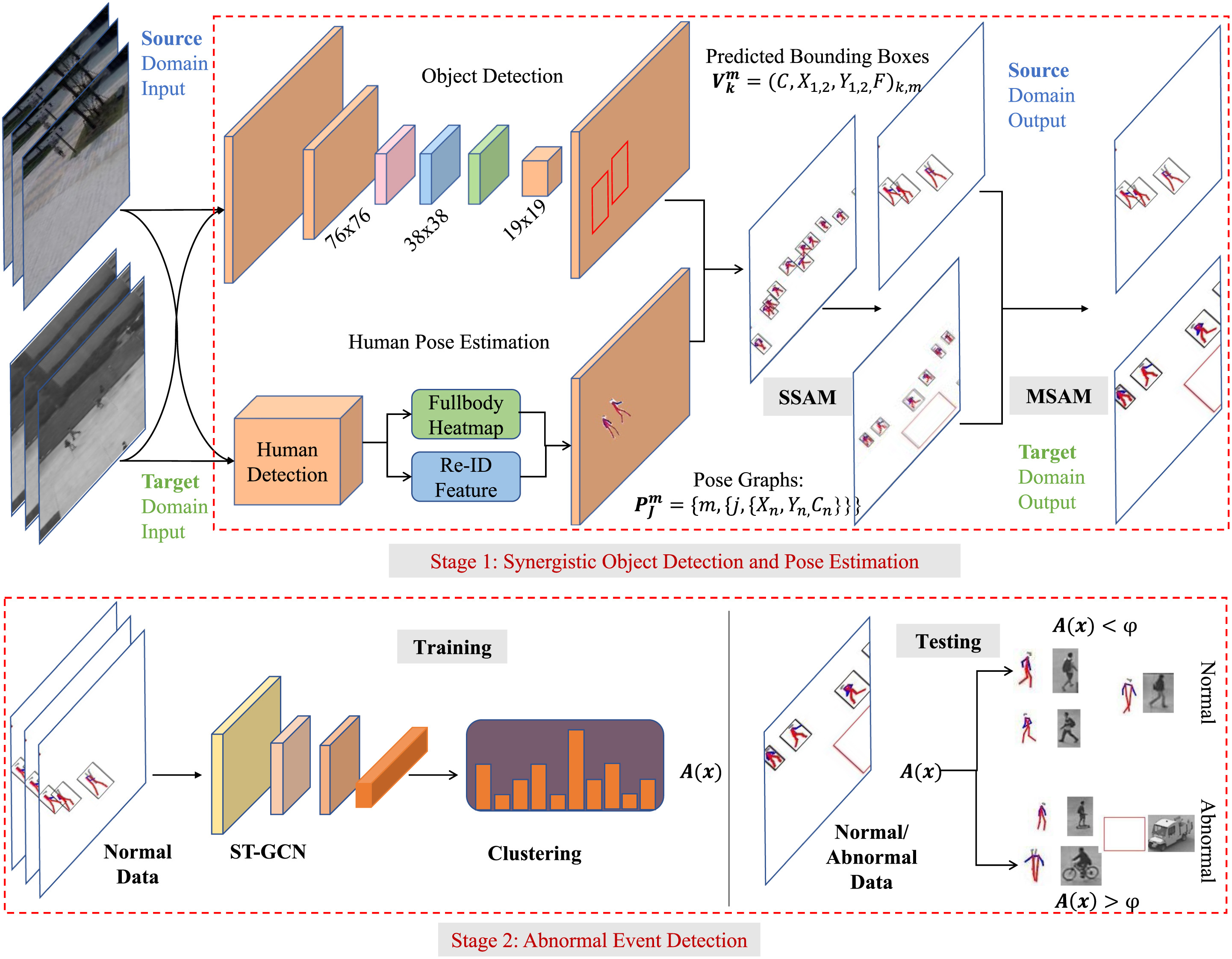
Proposed Method
This paper presents a novel, scene-adaptive framework that addresses the challenges in the existing AED methods by integrating human pose estimation and object detection. Our approach pipeline is illustrated in Fig. 3, which consists of several key steps, each serving a unique function in our system's architecture.
- Synergistic Pose Estimation and Object Detection: In the initial stage, our system leverages synergistic pose estimation and object detection to incorporate context class results effectively. This improves the accuracy of the pose information and helps bridge the gap between different scenes.
- Pose Sequence Generation: The system creates a series of pose sequences by effectively mapping the prior pose and class results. These pose sequences are further processed to generate more accurate and reliable data for subsequent stages.
- Spatio-Temporal Graph Convolutional Auto-Encoder (ST-GCAE): The generated pose sequences are then input into a spatial and temporal graph convolutional auto-encoder (ST-GCAE), a state-of-the-art model that excels at learning spatio-temporal feature representations. Based on these pose sequences, the ST-GCAE is trained to recognize normal human behaviours. It identifies patterns and relationships between the poses over time and space.
- Activity Clustering: A fully connected layer is appended to the ST-GCAE output to cluster human-related activities. This layer helps to group similar activities together and differentiate them from potentially abnormal events.
- Abnormality Detection: In the final decision-making stage, the system makes a determination on the abnormality of events at the frame level. This is done based on the integrated normality scores from the ST-GCAE and the object detection module. An event is flagged as abnormal if it deviates significantly from the learned normal patterns.
Results
The proposed method achieves state-of-the-art performance on multiple datasets:
ShanghaiTech Campus: 84.6% AUC (highest performance)
UCSD PED2: 96.9% AUC
UCSD PED1: 74.8% AUC
These results confirm the robustness and effectiveness of our proposed framework for cross-scene abnormal event detection.
Contributors





@article{YANG2025128673,
title = {Pose-oriented scene-adaptive matching for abnormal event detection},
journal = {Neurocomputing},
volume = {611},
pages = {128673},
year = {2025},
issn = {0925-2312},
doi = {https://doi.org/10.1016/j.neucom.2024.128673},
url = {https://www.sciencedirect.com/science/article/pii/S0925231224014449},
author = {Yuxing Yang and Leiyu Xie and Zeyu Fu and Jiawei Yan and Syed Mohsen Naqvi},
keywords = {Abnormal event detection, Scene-adaptive, Pose estimation, Object detection, Graph convolutions}}